Problema - reto de la
detección de contenidos web:
Desarrollar una tecnología que permita la detección de páginas web pornográficas mediante un análisis semántico en tiempo real.
El principal problema radica en que: No todo lo que dice sexo es pornografía, e incluso, las páginas con contenido sexual explícito o implícito podrían no contenerla.
Nos enfrentábamos al reto de detectar la palabra, pero más importante aún, el contexto en que se encuentra.
Cuando un usuario de Internet accede a una página web, la tecnología a desarrollar deberá detectar mediante una serie de verificaciones, el contenido de la página que se está consultado, con el objetivo de impedir que niños tengan acceso a material inadecuado para su edad y madurez mental.
Las tecnologías vigentes y líderes de 2006, lograban una detección en función de palabras detectadas, a través de un conteo y asignación de un valor a cada una (Dansguardian). Este método generaba un porcentaje inaceptable de falsos positivos en la detección y bloqueo de páginas.
Nuestra solución, contaría con una serie de mecanismos de detección y clasificación de los sitios web, siendo uno de estos, el analizador semántico. Reitero, este es solo uno de los múltiples mecanismos de detección, clasificación y reconocimiento de contenidos inadecuados.
Entonces, el contexto y propósito en que se emplea la palabra sexo (o cualquier otra), es el que da sentido y significado a la palabra.
Solución para
el filtrado de contenidos
En 2007 presenté el modelo a mis compañeros programadores para la construcción del algoritmo.
Este modelo permite la detección de una palabra o frase clave y su clasificación de acuerdo al contexto en la que se encuentra.
Explicaré el modelo considerando la palabra SEXO pero aclarando que una página pornográfica podría incluso no utilizarla, entonces esta particularidad da origen a lo siguiente:
1. Categorización.
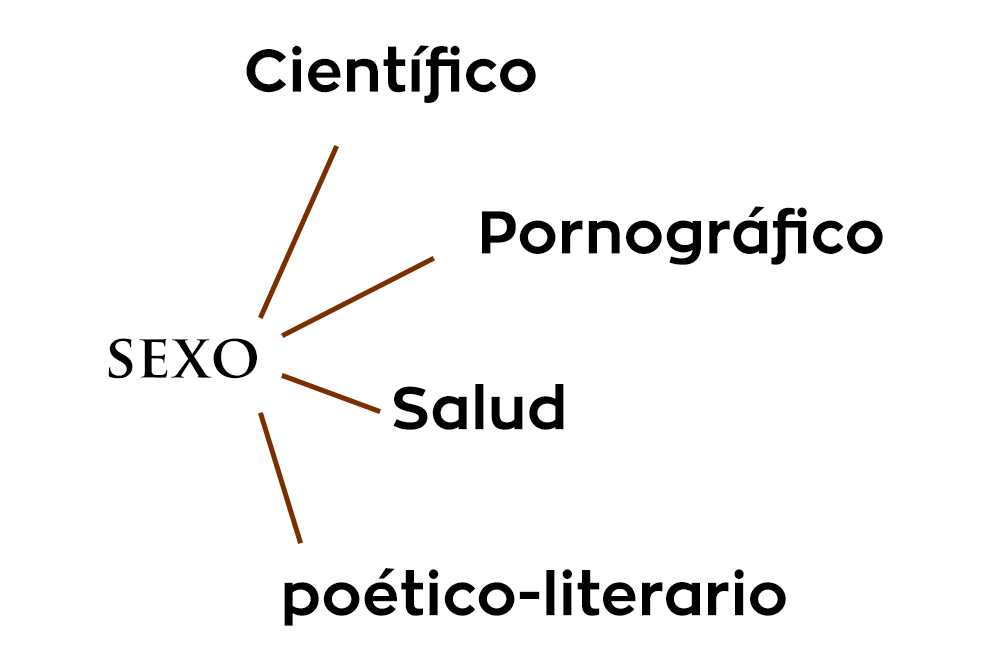
El interés se centraba en páginas con contenido sexual, sin embargo, bajo la premisa de que no todo el contenido sexual es pornográfico, establecimos las contextos en los que podíamos encontrar la expresión.
Categorías establecidas:
-
Pornografía (sexo explícito).
-
Sexo soft (sexo no explicito, erotismo).
-
Sexo y religión (sexo en un contexto histórico-religioso).
-
Sexo ciencia (biológico, científico, salud, prevención).
-
Sexshops y artículos.
-
Sitios de Citas.
2. Palabras clave y contextos.
Los contextos se refieren a :
1. Enfermedades venéreas.
2. Sistema reproductor masculino y femenino.
3. Sexo, tendencias, filias, prácticas: Significados y descripciones.
4. Masturbación, erotismo desde el punto de vista sicológico, biológico y siquiátrico.
5. Sexo, evolución, reproducción.
6. Trastornos.
Etcétera.
Un equipo de personas, con la ayuda de un robot (aplicativo), establecieron las palabras o frases clave de búsqueda en navegadores que permitiera la obtención de páginas web con el tema seleccionado, ejemplo "Enfermedades venéreas".
El resultado de esas páginas, fue analizado, calificado y guardado en un servidor para su análisis posterior.
De las páginas calificadas, se eliminaron todos los artículos, conjunciones, preposiciones y pronombres.
Una vez trabajadas las páginas, los resultados permiten visualizar nuevas palabras clave que son coincidentes en el grupo de páginas según su categoría y contexto.
Ejemplo de palabras o frases clave obtenidas en el contexto "Enfermedades Venéreas":
Sexo.
VIH/ SIDA.
Sexo oral.
Sexo anal.
vagina.
uso condón.
pene.
lengua.
miembro.
Enfermedades transmisión sexual.
Tratamiento.
Verrugas genitales.
Clamadia.
Genitales.
Gonorrea.
Sífilis
Hepatitis.
Herpes.
Virus.
ETS.
Infección.
Bacteria.
Coito.
bacteriana.
Transmite intercambio.
Riesgo contraer enfermedad.
Prácticas sexuales.
Múltiples parejas.
Etcétera, son cientos de palabras o frases clave.
Posteriormente se hace lo mismo considerando el idioma, en muchos casos simplemente aplica la traducción y en otros se replica todo el procedimiento en el idioma original deseado.
El resultado de este procedimiento es un listado de palabras y frases clave que son el contexto de la categoría en cuestión, en este ejemplo: Sexo ciencia.
Otro tratamiento que se debe hacer a las palabras, es obtener su conjugación; así palabras como penetración, se descompone en penetro, penetras, penetra, etcétera en todos sus tiempos y modos.
3. Separación y ordenamiento de palabras.
La solución consiste en separar las palabras y frases de contexto (las llamaremos D1) y las palabras que definen a la categoría (serán llamadas D2), mientras que palabras comunes de cada contexto deberán ser agrupadas ( las llamaremos C)

D2: Son las palabras o frases que se encuentran en prácticamente todas las categorías de sexo, por lo tanto no pueden ser usadas para definir el contexto. La palabra masturbación (una vez que se conjuga) se encuentra en todas las categorías, desde páginas pornográficas, hasta religiosas, por lo tanto, solo puede clasificarse como una palabra que define a la categoría pero no al contexto.
D1: Son las palabras que definen el contexto al relacionarse con las de categoría.
En el siguiente ejemplo, ordeno primero las D1 (contexto) y luego D2 (categoría) para obtener la categoría específica.
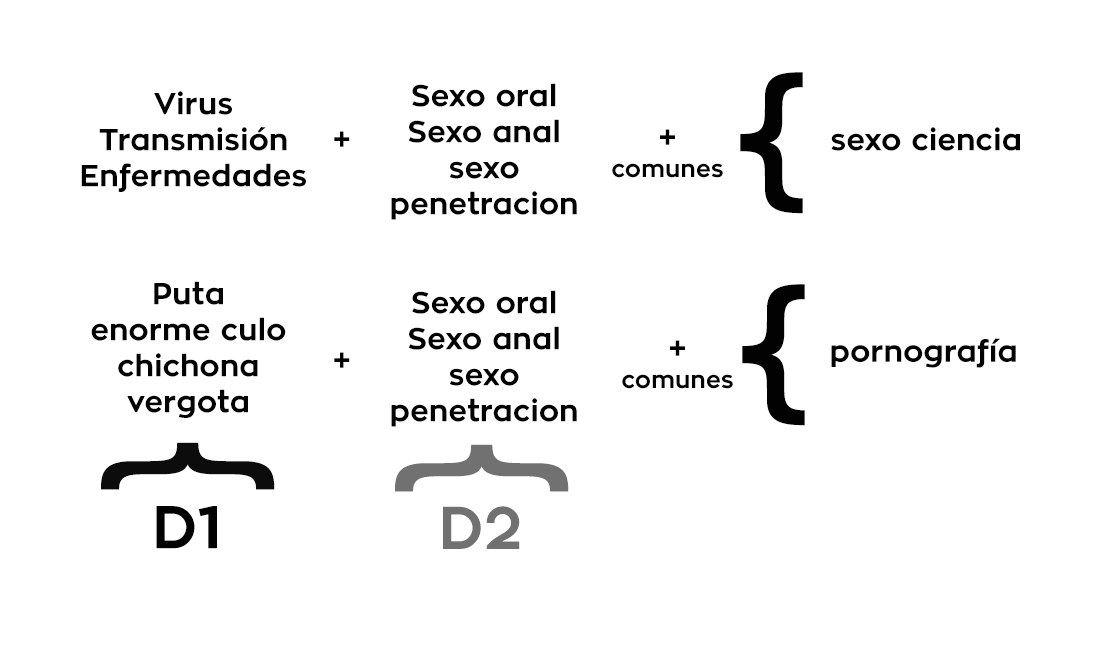
Tal como se observa en la imagen superior, el grupo de palabras que utilizo para D2 en las categorías de Sexo Ciencia y Pornografía, son las mismas. Claramente se puede apreciar que el grupo de palabras se puede encontrar prácticamente en cualquier tipo de sitios web que hablen de sexo sean o no pornográficos.
La identificación correcta se hace utilizando el grupo de palabras D1, de contexto, en asociación con D2, de categoría y en caso de que el procesamiento final arrojará ambigüedad en el resultado, se utilizan las comunes para determinar con exactitud el contenido.
4. Conteo y correlacionamiento.
Incluso, se puede obtener, por ejemplo, tres D1 de sexo ciencia, siete D1 de sexo y religión con cuatro D2 y en la misma página, este resultado indica que estamos ante un sitio web de contenido sexual en contexto religiosos que además aborda el tema sexual de forma científica, dos categorías específicas detectadas.
Nuestro filtro se programó para indicar hasta tres categorías en una página web. Estas tres categorías se presentaban de forma más constante en la detección de páginas de Citas sexuales las cuales incluyen pornografía y sexo soft o cualquier combinación de estas.
Para eliminar posibles falsos positivos en la detección, realizamos una matriz que indicaba relaciones esperadas respecto al número de palabras contenidas en la página y las D1, D2 y C que se podrían esperar según el tamaño del texto, por ejemplo, en una página con 5000 palabras y con detección de solo una D1 y una D2, no se consideraría positivo el match en virtud de que el tamaño del texto y la sustancia del contenido debería ser mucho mayor en D1 y D2.
Tampoco se hace un match positivo cuando solo se encuentran D2 sin D1, en estos casos, se estaría hablando que las palabras de categoría aparecieron de forma incidental o banalmente abordadas por el sitio. A la inversa ocurre lo mismo, de solo presentarse detección de D1, se estaría en presencia de una página que habla de enfermedades, historia, ciencia pero no relacionadas con sexo por lo que no haría match.
Cuando el texto es menor a 250 palabras, basta una correlación de una D1 con una D2 para dar positivo en el match.
Programación del algoritmo
Cuando terminamos las pruebas y pasamos a la versión 1 del algoritmo, fue actualizado dentro de Carmela para el primer lote de pruebas con la tecnología de la Policía Federal, resultados que presento en la sección Carmela del menú principal.
La programación del algoritmo la realizó mi compañero:
Ing. Ángel Áxel González.
cgslp@inglobalcom.com
El posterior mantenimiento al mismo estuvo a cargo de: